作者介绍

背景
随着科研工作的复现失败的问题越来越频繁的出现,人们发现其中一个重要原因就是分析过程中的灵活性。
如何划定异常的边界值?哪些协变量需要考虑,而哪些被忽略?种种选择稍有不慎就可能导致结果相差甚远甚至得出相反的结论。
因此,这种灵活性更多的属于一种不严谨的方法甚至是主观臆断,从而降低了结果的可信度,需要尽可能避免它。
这方面代表性的工作之一称为平行宇宙分析。顾名思义,在定义了分析空间之后,对所有可能的组合情况中那些合理的分析路线进行穷举,最终采用最显著的选项用于支撑决策。这样子得到的结果更加科学,并且具备自解释性。
人们需要一个交互式分析工具帮助理解,提高效率。
贡献
本文的贡献是Boba领域特定语言(DSL)和平行宇宙可视化分析系统。
相关工作
平行宇宙分析
1. 筛选合理的分析决策
2. 穷举所有合适的决策组合
3. 汇总解释决策结果
编写可选的程序和设计
- 大多数历史追踪工具
- 仅支持同时分析一个版本
- 多版本同时分析工具
- 效率不高,通用性不足
流程
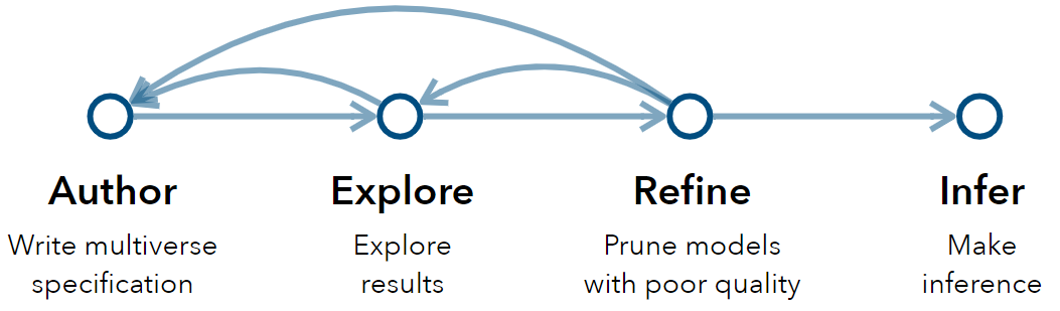
用户定义平行宇宙空间->探索结果->通过微调模型来优化平行宇宙->->循环前面三个步骤,直到满意后再做出推断。
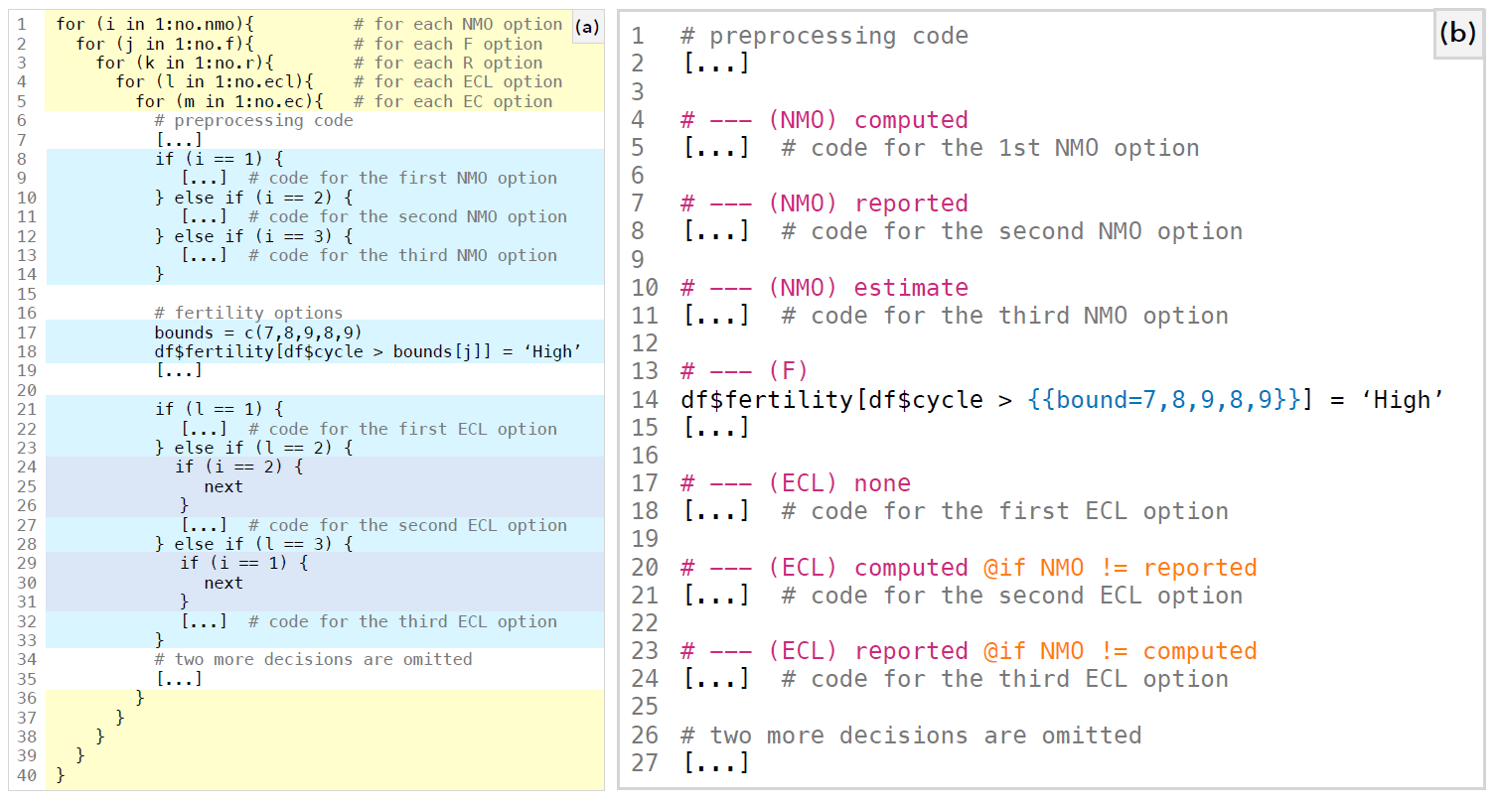
DSL的定义
源代码:可以是任何编程语言
占位符变量:作为决策点划分的依据
代码块:顾名思义。A: 普通块,共享的。M:决策块,每次只出现一个
约束:作为决策块是否出现的条件,用于剪枝
代码图:每个代码块作为节点,代码块之间的顺序作为有向边,得到的有向无环图

DSL示例
图中左侧代码部分是一个包含五个决策的平行宇宙。
左侧问题:嵌套太深,难以阅读。直接执行效率也低下。鲁棒性差,一旦某一次循环错误,内部的循环会产生连锁反应。
右侧代码:抛弃了外层的for循环,线性逻辑。彼此之间互相独立。
场景分析
假设我们现在是一个网站运营者。最近刚上线了新版的网页设计,通过收集数据发现阅读的速度有了一定提升。现在我们希望分析阅读速度提升究竟和网页设计改版是真的有关还是巧合。
为了确保我们的结论在分析决策上是鲁棒的,我们首先需要对决策项进行定义,除了阅读速度之外,还需要考虑一下6个决策项:是否需要排除操作阅读障碍人群、是否排除特定设备类型的用户、是否排除结果准确性低的用户、使用什么统计模型、定义哪些随机项和定义哪些固定项。基于以上定义,我们建立一个以阅读速度为依赖变量的模型。通过先前设计的领域特定语言模型进行编译得到216个分析脚本,并把结果进行可视化。
假设我们现在是一个网站运营者。最近刚上线了新版的网页设计,通过收集数据发现阅读的速度有了一定提升。现在我们希望分析阅读速度提升究竟和网页设计改版是真的有关还是巧合。首先是数据定义,除了阅读速度这一数据,还需要收集操作阅读障碍情况、设备类型、准确性、人口统计模型、随机项和固定项。基于以上6项数据也就是决策指标,我们建立一个以阅读速度为依赖变量的模型。通过先前设计的领域特定语言模型进行编译得到216个分析脚本,并把结果进行可视化,如下所示。

左侧:决策视图,也就是之前的代码图。每个节点代表一个决策,灰色的边代表时间顺序,也就是代码中的先后位置;黑色有向边表示程序依赖关系。节点的半径大小编码决策所包含的选择的数量,节点左边列出了其中几个可能的值; 节点的颜色深度编码了敏感程度大小,敏感程度反映了分布之间的差异大小,这是通过自动算法直接得出的。注意到设备类型节点颜色很深,说明与他相关的分布之间存在比较大的差异,这一点可以通过右侧的结果视图得到印证。
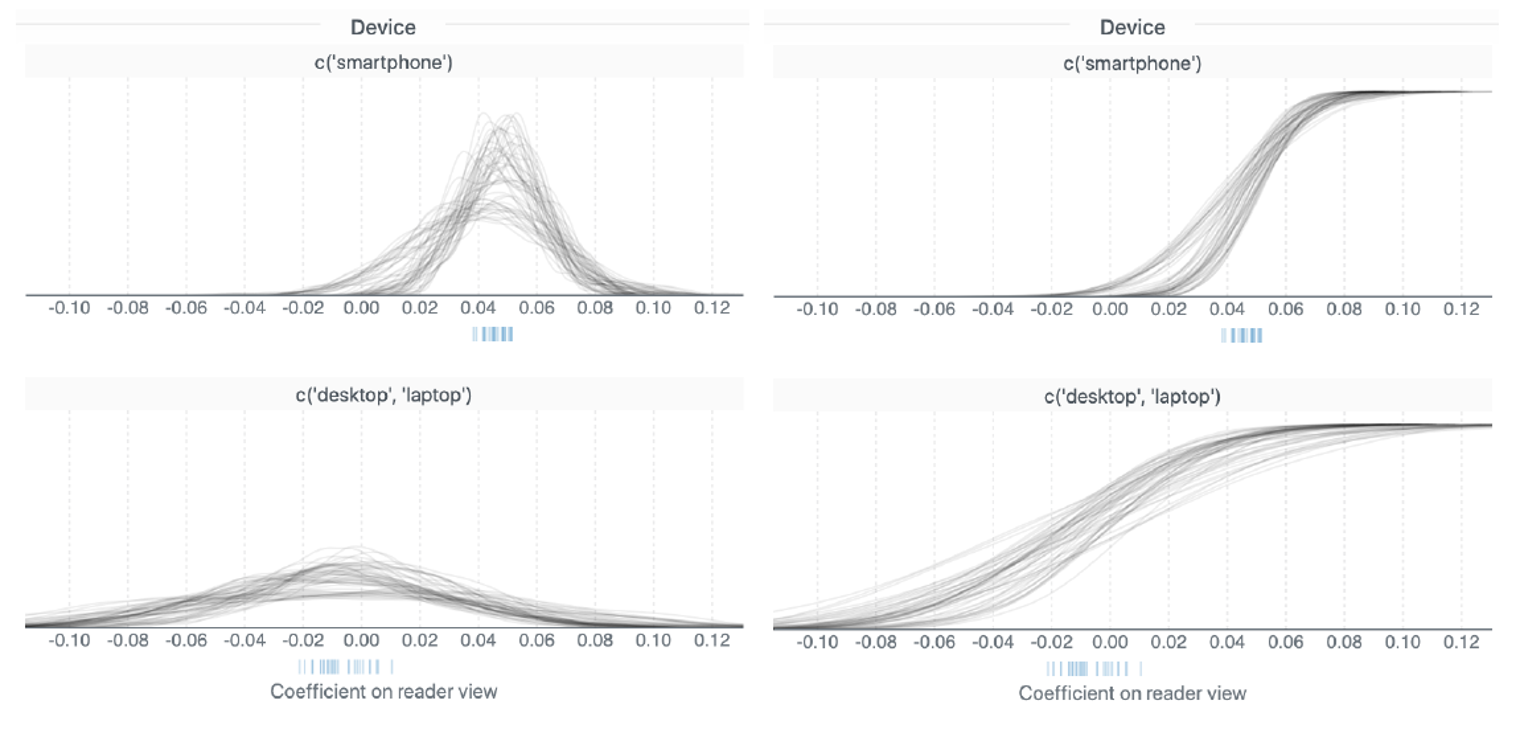
右侧:密度图,比传统直方图更加精确,同时能够适应大数据量。背后的灰色区域是不确定性指标,通过在y轴上进行缩放使得其面积和密度图一样。
本图中有两个峰,右侧的coefficient大于0,正相关,而左侧的峰小于0,是负相关,二者得出的结论相矛盾。
PDF:概率密度函数
CDF:累积分布函数
在线上加了透明度来合并在空间上重叠的线。
蓝色条纹表示点估计。
点开device节点后,可以看到其中每个取值的详情视图。
我们发现desktop部分的coefficient<0,当我们刷选这部分区域后,得到下方的选择比例视图。
在该视图中,每个决策表示为一个stacked bar chart,层叠柱状图。
Device是当前选项所在的决策,所以用了特殊纹理进行标记。其他的每个决策的每段bar代表当前结果来自其各个选项的比例。 影响显著的会用深色高亮出来。可以看出Model中的Lmer和和Fixed中的两项都有显著影响。

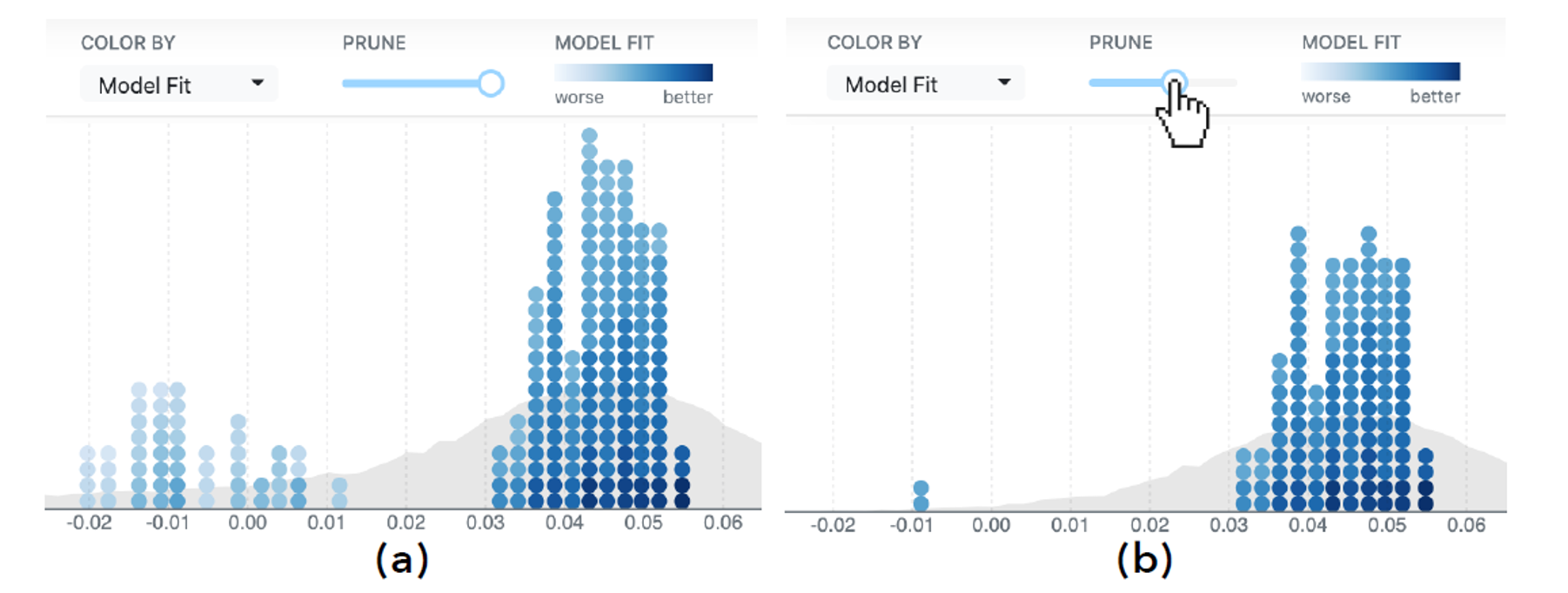
模型微调。圆点的颜色深浅编码了各个决策模型拟合的质量高低(归一化均方根误差)。通过拖动滑动条可以过滤掉那些质量较低的决策线路。
至此,我们已经完成了流程中的前三步:定义平行宇宙空间->探索结果->通过微调模型来优化平行宇宙,到了最后一步:推断结论了。
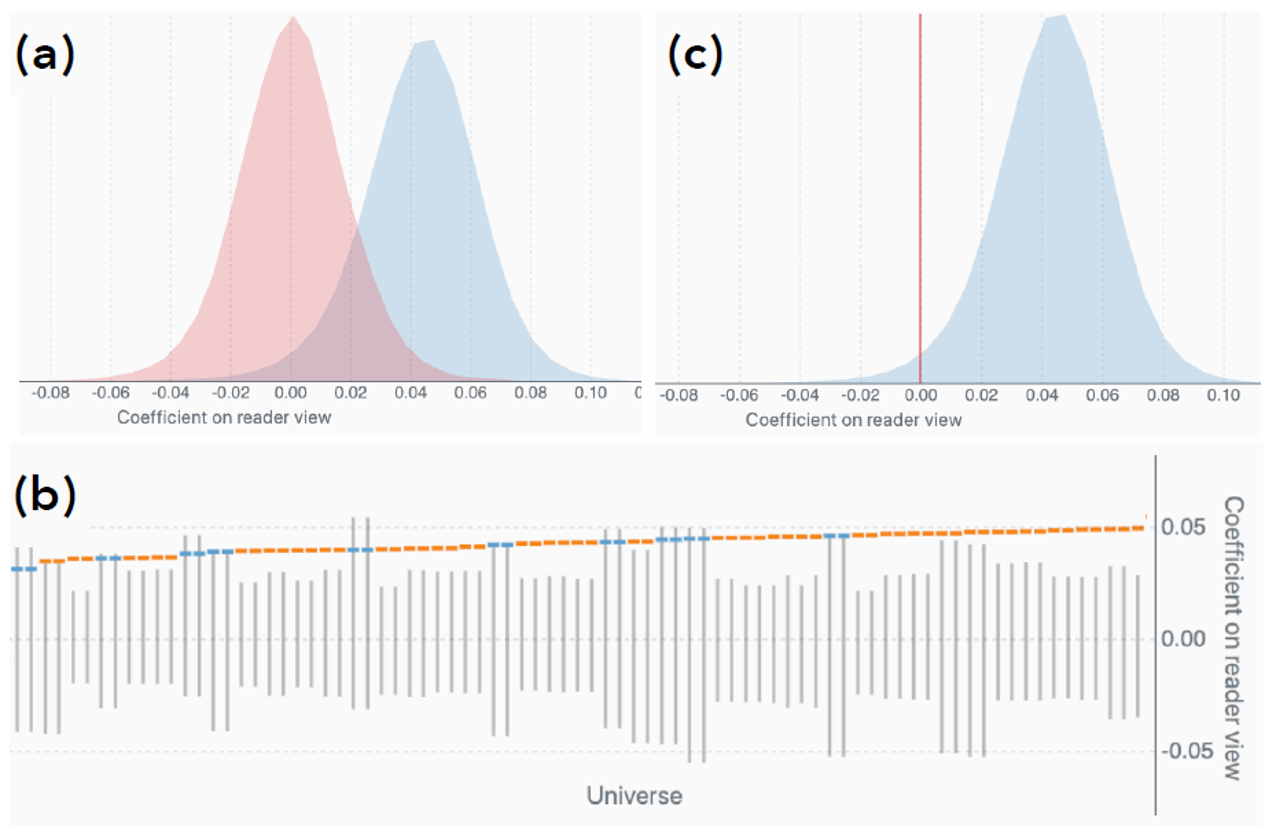
(a)中的蓝色部分是当前得到的平行宇宙的分布结果,红色部分是一个空分布,也就是假设结果与任何预先定义的决策变量都无关模拟出来的,作为蓝色真实结果部分的参照。有的情况下这个空分布无法计算,就用(c)中的直线作为替代。
(b)中表示每个宇宙单元的数据,灰色的样条表示空分布的分布结果。橙色点表示该宇宙的结果落在空分布之外,表现为与灰色样条不相交。蓝色点表示该宇宙的决策结果落在空分布之中,表现为和灰色样条相交。
案例分析
问题:女性用户是否更容易借贷成功?
这个问题包括用到的数据集都是来自17年的一篇工作。当时作者手动设计了许多可视化来实现多模型分析流程,得到了一些有趣的发现。但由于平行宇宙分析的空间过于巨大,因此当时的分析还是偏粗粒度的,没能挖掘出很多细微的模式。本文的这个case就重现了这套分析流程,视图在挖掘出更多内容的同时,保证更高的效率。
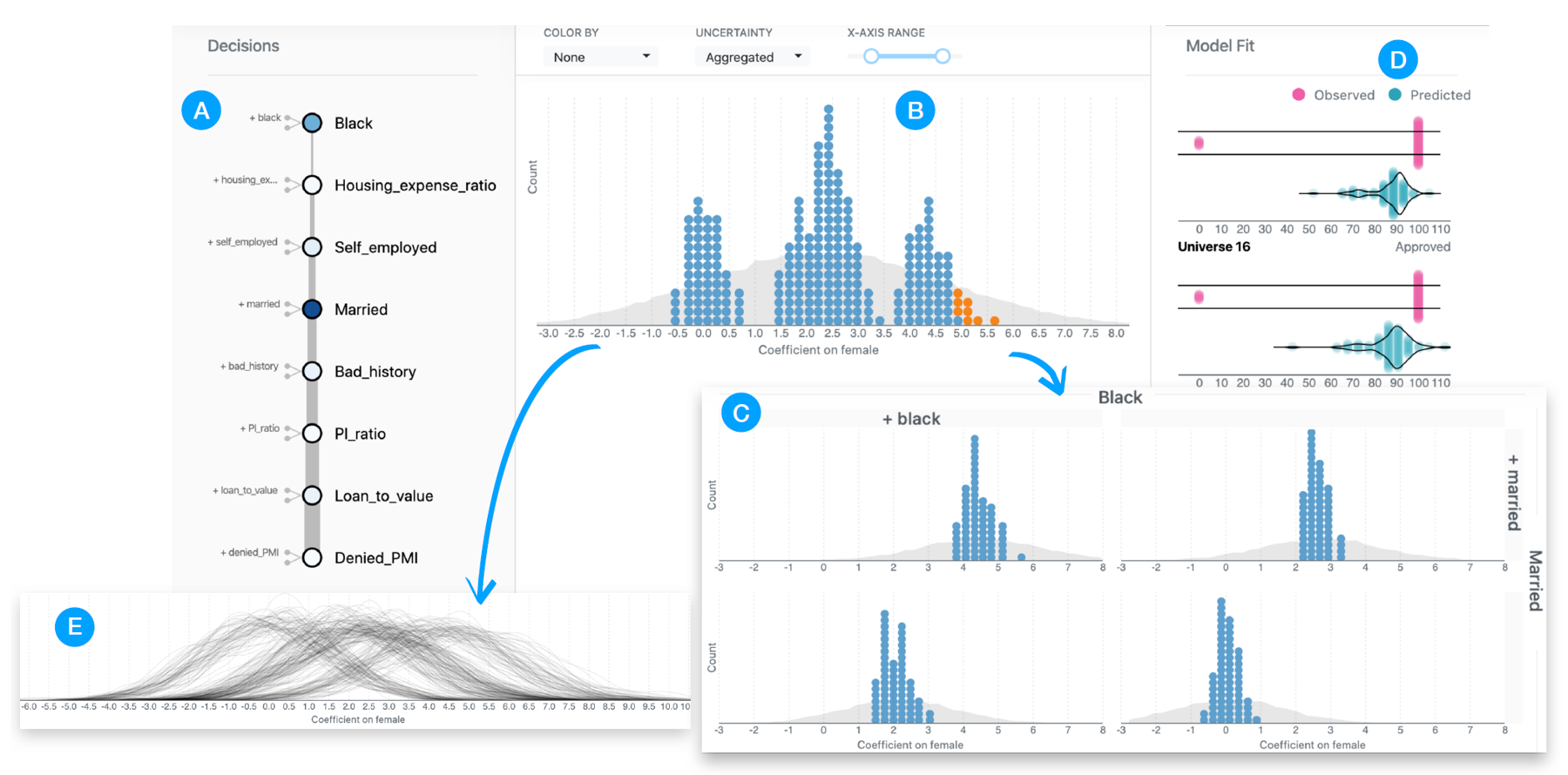
(a)肤色和婚姻状况这两个决策指标显示为高敏感度。
(b)中的灰色的不确定性指标分布范围比较大,反映了不同决策下结果相差很大。
这两点结果和之前的工作结论是一致的。下面来看发现的具体模式
(b)中可以看出数据呈现为多模型分布,表现为3个分开的峰。
分别点开(a)中的两个敏感节点,我们可以看出3个峰中的左右两个分别可以落在(c)的右下角和左上角。
(e)中的pdf曲线反应数据整体分布其实还是一个单模型,说明采样率的不同对结果也会产生影响。
(d)使用了logistic回归模型对结果进行拟合,可以看到对于二值分布的结果还是拟合的很好的。
未来工作
- 引入专家知识,扩展适用人群
- 优化平行宇宙的执行性能
- 开发高性能的Debugger工具
- 考虑决策的统计依赖关系,杜绝偏见
- 在避免偏见的前提下提高模型调优的灵活性
✉️ zjuvis@cad.zju.edu.cn